PRTG – ADC zentralisiert via ADM überwachen (Zusammenfassung)
In den letzten Tagen habe ich ein paar einzelne Beiträge verfasst, wie man Citrix ADC/NetScaler mittels Citrix ADM im PRTG überwachen kann. In diesem Artikel möchte ich noch einmal kurz darauf eingehen, warum überhaupt und ich möchte euch auch alle Beiträge gesammelt auflisten.
Bevor wir ADM im Einsatz hatten, waren unsere ADCs alle einzeln vom PRTG überwacht. Voraussetzungen dazu waren dann
funktionierende Sensoren für die ADCs
PRTG Logins auf jeder einzelnen Appliance
PRTG Netzwerkzugriff auf jede einzelne Appliance
Pflege aller ADC Geräte und inklusiv aller Sensoren im PRTG
Gerade in Umgebungen mit limitiert lizenzierten PRTG Sensoren ist der letzte Punkt auch ein Kostenfaktor. Für mich waren vor allem zwei Punkte entscheidend um das Konstrukt umzubauen:
die eingesetzten Sensoren gaben öfter auch einmal „false positive“ Alarme aus
im eingesetzten vServer Statussensor konnte nicht ein einzelner vServer bestätigt werden, falls dieser einmal DOWN war – somit konnte ein ‚DOWN‘ vServer einer Testapplikation das komplette Monitoring ausser Kraft setzen
Warum also nicht ADM nutzen wenn schon alle ADCs darüber verwaltet werden? Dies hat für mich folgende positive Effekte:
nur ADM benötigt Netzwerkzugriff auf jede einzelne Appliance
es wird nur auf dem ADM ein PRTG Login benötigt
es müssen nur die Sensoren für den ADM gepflegt (und lizenziert) werden
ein einzelner vServer der DOWN ist, kann im ADM bestätigt werden und die PRTG Überwachung läuft wie gewohnt weiter
und wer Lust und Laune hat, kann weitere Sensoren skripten falls gewünscht
Um dies nachzubauen, könnte ihr gem. folgenden Artikeln vorgehen:
Zu guter Letzt fragt ihr euch vielleicht, was der Spass kostet? Also Zahlen nenne ich hier nicht, aber Stand heute müsst ihr das PRTG entsprechend eurer Umgebungsanforderung lizenzieren (evtl. reichen ja die 100 Gratissensoren). Die ADCs habt ihr gem. euren Bedürfnissen gekauft oder als Freemium im Einsatz. Und ADM könnt ihr für die genannten Funktionen ebenfalls ohne zusätzliche Lizenz nutzen. Das einzige was es garantiert benötigt, sind die Hardwareressourcen gemäss Spezifikationen und eure Zeit.
Viel Spass und Erfolg beim Nachbauen. :-)
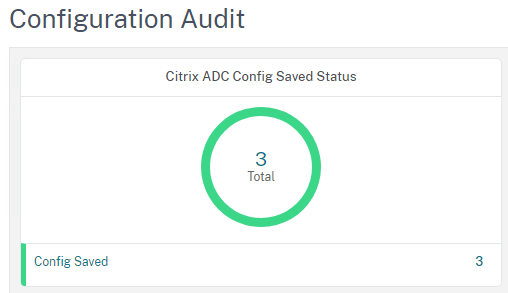
PRTG – Citrix ADM Nutzen um ungespeicherte ADC Konfigurationen zu überwachen
Im einem der letzten Beiträge habe ich ein Powershell Modul vorgestellt, mit welchem man Daten vom Citrix ADM abgreifen kann.
Basierend auf diesem Modul habe ich bei uns einen PRTG Custom Sensor erstellt, welcher ungespeicherte Konfigurationen aus dem ADM ausliest:
Dazu müssen erst einmal die Parameter von PRTG sowie das Modul selbst eingelesen und eine Verbindung zur Appliance hergestellt werden:
Damit dies funktioniert, muss der entsprechende Benutzer von PRTG auf dem ADM Leserechte haben. Weiter gehe ich nicht auf jede Zeile ein, dies kann im Script selbst nachgelesen werden. Hier beschreibe ich vor allem die wichtigsten Punkte, wie das auslesen der Konfigurationsdaten aus dem ADM:
# Get the config status from the ADM
$DiffEvents = Invoke-ADMNitro -ADMSession $ADMSession -OperationMethod GET -ResourceType ns_conf
# Create the variable only with the active events content
$DiffEvents2 = $DiffEvents | Select-Object ns_conf
Nun werden die Daten noch auf den String „Diff Exists“ geprüft und für die weitere Auswertung aufbereitet. In diesem Sensor gibt es nur einen guten oder schlechten Rückgabewert, weshalb der Block sehr kurz gehalten ist:
$Events = @()
ForEach ($Event in $DiffEvents2.ns_conf){
If ($Event.diff_status -eq "Diff Exists"){
# Filter out 'entityup' messages from critical state
$RetState = $returnStateCritical
$Events += [PSCustomObject]@{Severity=$Event.hostname;SourceIP=$Event.ns_ip_address;SourceHost=$Event.hostname;State=[Int64]$RetState}
$RetCritical = $RetCritical + 1
}
}
Im restlichen Skript wurden die einzelnen Daten mit einem vorgegebenen Wert gegen geprüft und die entsprechenden PRTG Ausgaben definiert.
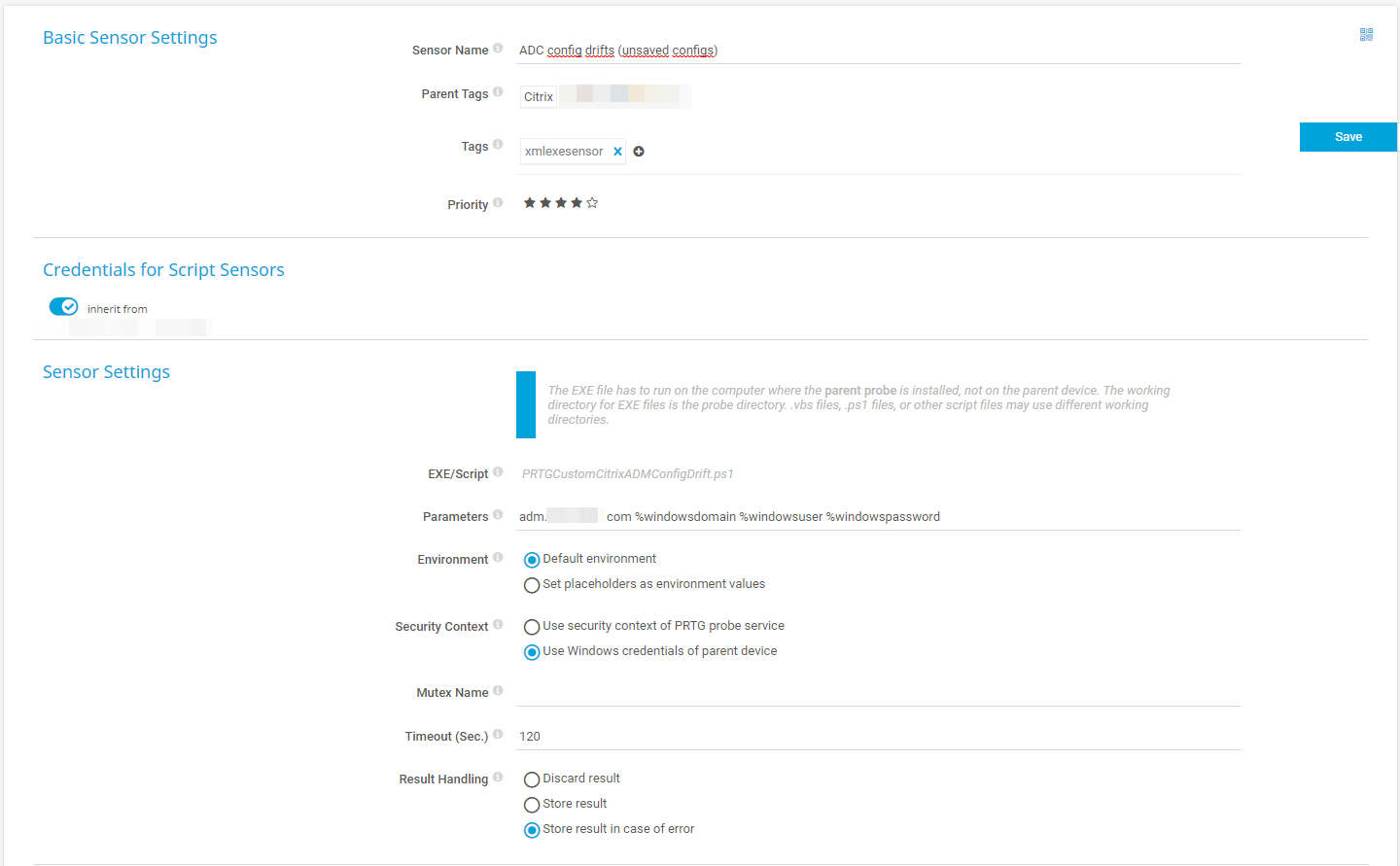
Das Script muss nun in den Custom Sensors Ordner von PRTG gelegt werden und der Sensor kann entsprechend eingerichtet werden:
Parameter gem. Script-Beschreibung, Securitykontext vom GerätDer Intervall wird ein wenig höher gestellt, damit bei aktiven Änderungen das Monitoring nicht sofort Alarm schlägt.
Damit dies funktioniert, muss der entsprechende Benutzer von PRTG auf dem ADM Leserechte haben. Weiter gehe ich nicht auf jede Zeile ein, dies kann im Script selbst nachgelesen werden. Hier beschreibe ich vor allem die wichtigsten Punkte, wie das auslesen der Performance-Daten sowie das Sortieren nach Appliance:
# Get the Instances from the ADM
$ADCInstance = Invoke-ADMNitro -ADMSession $ADMSession -OperationMethod GET -ResourceType ns
# Create the variable only with the NS parameters
$ADCInstance2 = $ADCInstance | Select-Object ns
# For troubleshooting
#$ADCInstance2.ns | FT hostname, ns_mgmt_cpu_usage, ns_cpu_usage, vm_memory_usage, diskperusage, disk0_used, disk1_used, ns_tx, model_id -AutoSize
$ADCInstances = $ADCInstance2.ns
# Sort output based on hostname
$ADCInstances2 = $ADCInstances | Sort-Object hostname
Da das Web GUI von PRTG nicht nach Channel ID sondern nach Alphabet sortiert, habe ich für die Channel-Namen jeweils noch einen eigenen Index erstellt. A0 ist reserviert für den „Overall Health“ Status (weiter unten beschrieben). Anschliessend kriegt jede Appliance einen eigenen Buchstaben und innerhalb einer Appliance wird hochgezählt:
$ChannelLetterIndex = 65 # Start index with 65 for ASCII 'A'
ForEach ($Instance in $ADCInstances2){
#region returnvariables
$ChannelLetterIndex = $ChannelLetterIndex + 1 # Increase letter index by one for each appliance instance
$RetChannelLetter = [char]($ChannelLetterIndex)
Im PRTG werden Prozentwerte nur in ganzen Zahlen angezeigt, daher werden die entsprechenden Werte gerundet:
Die prozentuale Bandbreiten-Auslastung wird anhand der Werte sowie der Model ID berechnet. Da diese im Test oft exponentielle Werte lieferte und diese nicht gerundet werden können, musste dies via Umwandlung in einen String gemacht werden:
#region bwcalculation
# Calculate the percentage of the bandwidth usage
# based on the license and the current bandwith
# A conversation to string is needed because of the
# exponential results which needed to be trimmed
$BWPercentCalc = $null
$BWPercent = $null
$BWPercentCalc = $Instance.ns_tx*100/$Instance.model_id
$BWPercentString = [String]$BWPercentCalc
If ($BWPercentString.Length -ge 5){
$SubLength = 5
}
Else {
$SubLength = $BWPercentString.Length
}
$BWPercentStringShort = $BWPercentString.Substring(0,$SubLength)
$BWPercentShort = [Decimal]$BWPercentStringShort
$RetBWPercent = [math]::Round($BWPercentShort)
#endregion bwcalculation
Im restlichen Skript wurden die einzelnen Daten mit einem vorgegebenen Wert gegen geprüft und die entsprechenden PRTG Ausgaben definiert.
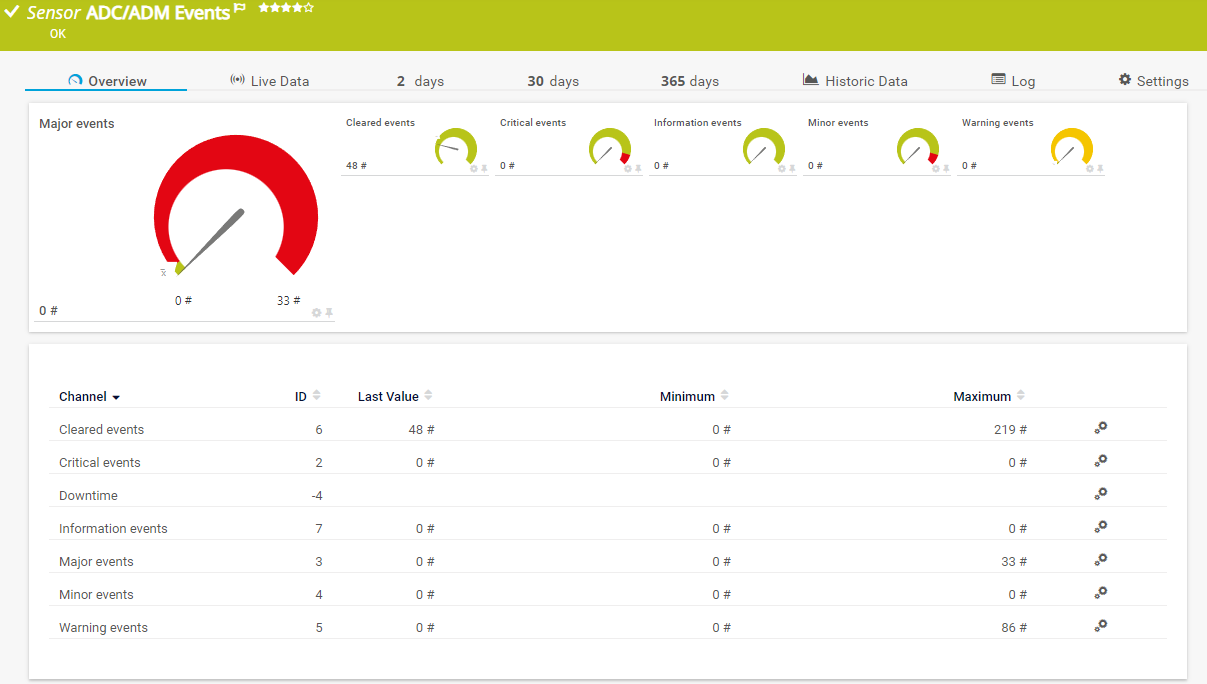
Zu guter Letzt wird aus allen vorher berechneten Werten ein Channel mit einer Gesamtbewertung der Performance erstellt, welche mit dem hardcoded Index A0 auch ganz oben gelistet wird:
Damit dies funktioniert, muss der entsprechende Benutzer von PRTG auf dem ADM Leserechte haben. Weiter gehe ich nicht auf jede Zeile ein, dies kann im Script selbst nachgelesen werden. Hier beschreibe ich vor allem die wichtigsten Punkte, wie das auslesen der Events:
# Get the events from the ADM
$ActiveEvents = Invoke-ADMNitro -ADMSession $ADMSession -OperationMethod GET -ResourceType active_event
# Create the variable only with the active events content
$ActiveEvents2 = $ActiveEvents | Select-Object active_event
Es sollen im PRTG nicht alle ADM Meldungen gleich einen Alarm auslösen, daher habe ich div. Arrays für Ausschlüsse vorbereitet, welche bei Bedarf genutzt werden können:
# Prepare a device_entity_name exlusion list for PRTG outputs
# Add each device in quota with a comma (except the last line)
$DeviceExcludeList = $null
$DeviceExcludeList = @(
"entity1",
"entity.domain.pit"
)
# Prepare a failureobj exlusion list for PRTG outputs
# Add each failure object in quota with a comma (except the last line)
$FailureObjectExcludeList = $null
$FailureObjectExcludeList = @(
"object1",
"object2"
)
# Prepare a message exlusion list for PRTG outputs
# Add each message in quota with a comma (except the last line)
$MessageExcludeList = $null
$MessageExcludeList = @(
"192.168.99.99"
)
Da auch vServer und Services vom ADC welche wieder hochkommen einen „Critical Event“ darstellen, habe ich diese beim Aufbereiten ausgeklammert:
If ($Event.severity -eq "Critical"){
# Filter out 'entityup' messages from critical state
If ($Event.category -ne "entityup"){
$RetState = $returnStateCritical
$Events += [PSCustomObject]@{Severity=$Event.severity;SourceIP=$Event.source;SourceHost=$Event.hostname;Category=$Event.category;Entity=$Event.device_entity_name;State=[Int64]$RetState}
$RetCritical = $RetCritical + 1
}
}
Innerhalb der „Major Events“ werden im ersten Schritt die vorher definierten Ausschlüsse gegengeprüft und mittels Variable $DeviceAlarm die weitere Verarbeitung bestätigt oder gestoppt:
# Filter out known entities, failure objects etc. from major state
# Set variable $DeviceAlarm, if the device isn't filtered
$DeviceAlarm = $null
ForEach ($ExcludedDevice in $DeviceExcludeList) {
$Entity = $Event.device_entity_name
If ($DeviceAlarm -or ($DeviceAlarm -eq $null)) {
If ($Entity -notlike "*$ExcludedDevice*") {
$DeviceAlarm = $true
}
Else{
$DeviceAlarm = $false
}
}
}
If ($DeviceAlarm){
ForEach ($ExcludedFO in $FailureObjectExcludeList) {
$Entity = $Event.failureobj
If ($DeviceAlarm -or ($DeviceAlarm -eq $null)) {
If ($Entity -notlike "*$ExcludedFO*") {
$DeviceAlarm = $true
}
Else{
$DeviceAlarm = $false
}
}
}
}
If ($DeviceAlarm){
ForEach ($ExcludedMessage in $MessageExcludeList) {
$Entity = $Event.message
If ($DeviceAlarm -or ($DeviceAlarm -eq $null)) {
If ($Entity -notlike "*$ExcludedMessage*") {
$DeviceAlarm = $true
}
Else{
$DeviceAlarm = $false
}
}
}
}
Falls ein „Major Event“ nicht durch einen Ausschluss gefiltert wurde, wird die Eventliste entsprechend aufbereitet. In diesem Schritt werden Meldungen von Services („svc“ im Namen) oder Service Groups („svg“ im Namen) zu einer Warnung herunter gestuft. Dies weil definiert wurde, dass im PRTG erst ein Alarm erscheint, wenn der komplette vServer und nicht ’nur‘ ein Service DOWN ist:
# If device isn't excluded, add to monitoring array
# Services (svc) or service groups (svg) returns a warning instead an alarm
If ($DeviceAlarm){
If (($Event.device_entity_name -like "*svc*") -or ($Event.device_entity_name -like "*svg*")) {
$RetState = $returnStateWarning
$Events += [PSCustomObject]@{Severity=$Event.severity;SourceIP=$Event.source;SourceHost=$Event.hostname;Category=$Event.category;Entity=$Event.device_entity_name;State=[Int64]$RetState}
$RetWarning = $RetWarning + 1
}
Else {
$RetState = $returnStateCritical
$Events += [PSCustomObject]@{Severity=$Event.severity;SourceIP=$Event.source;SourceHost=$Event.hostname;Category=$Event.category;Entity=$Event.device_entity_name;State=[Int64]$RetState}
$RetMajor = $RetMajor + 1
}
}
Im restlichen Skript wurden die einzelnen Daten mit einem vorgegebenen Wert gegen geprüft und die entsprechenden PRTG Ausgaben definiert.
Das Script muss nun in den Custom Sensors Ordner von PRTG gelegt werden und der Sensor kann entsprechend eingerichtet werden:
Parameter gem. Script-Beschreibung, Securitykontext vom Gerät
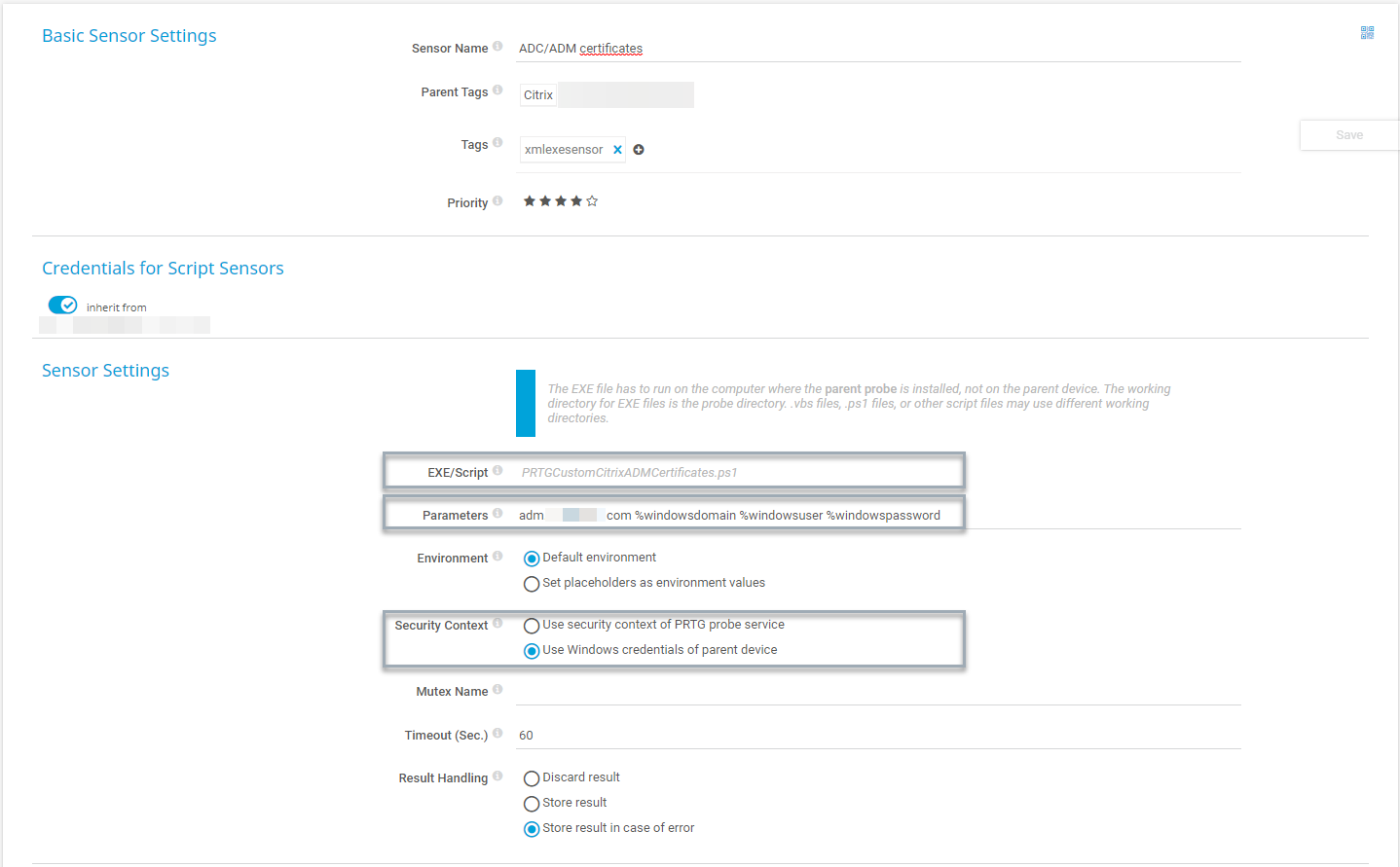
Damit dies funktioniert, muss der entsprechende Benutzer von PRTG auf dem ADM Leserechte haben. Weiter gehe ich nicht auf jede Zeile ein, dies kann im Script selbst nachgelesen werden. Hier beschreibe ich vor allem die wichtigsten Punkte, wie das auslesen der Zertifikate:
# Get the certificates from the ADM
Invoke-ADMNitro -ADMSession $ADMSession -OperationMethod GET -ResourceType ns_ssl_certkey
$ActiveCerts = Invoke-ADMNitro -ADMSession $ADMSession -OperationMethod GET -ResourceType ns_ssl_certkey
Das Ablaufdatum konnte nicht einfach so verwendet werden, daher musste ich mittels einer Funktion dieses erst in einen String umwandeln und dann entsprechend sortiert wieder zurück geben:
# Function ConvertTo-DateTime
# Converts the dates from the certificates to a standardized format
Function ConvertTo-DateTime([string] $datetime) {
# Removes double spaces
$datetime2 = $datetime -replace '\s+',' '
# Create an array and use the space as separator
$arr = $datetime2 -split ' '
# Reorder and create a readable date
$validdate = $arr[3] +"-"+ $arr[0] +"-"+ $arr[1] +" "+ $arr[2]
# Return the value
return $validdate
}
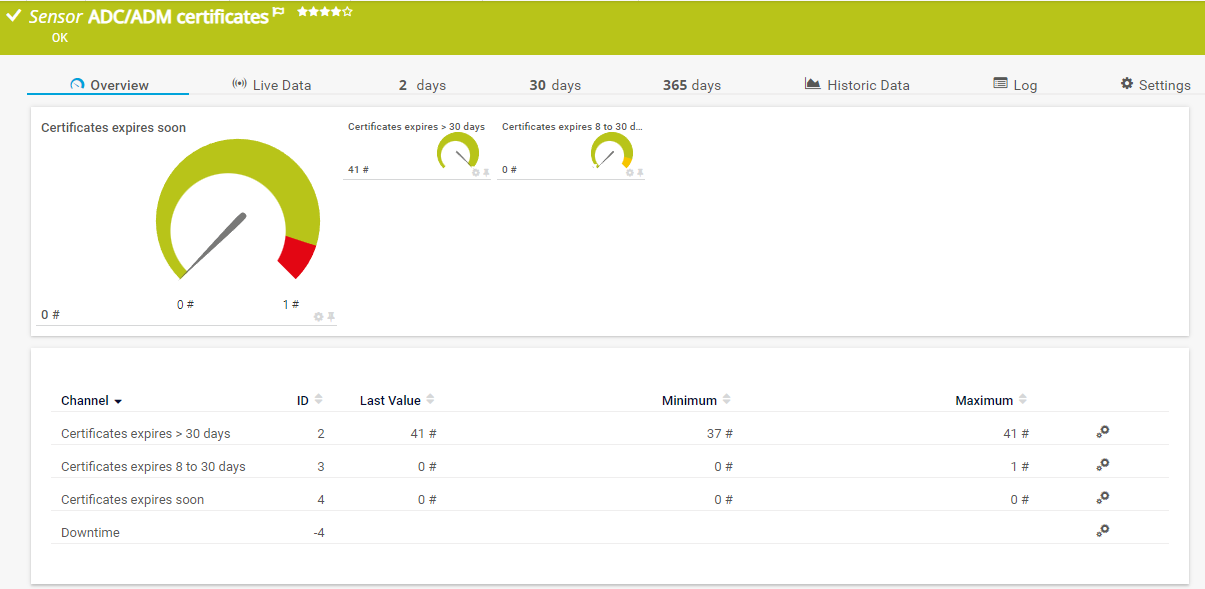
Nun konnte ich jedes Zertifikat einzeln in ein Array schreiben mit den entsprechenden Common Names und Ablaufdaten:
# Create array with all the certification information
ForEach ($Cert in $ActiveCerts2.ns_ssl_certkey){
$CertSubject = ($Cert.subject -split "," | ConvertFrom-StringData).CN
$CertIssuer = ($Cert.issuer -split "," | ConvertFrom-StringData).CN
$CertValidTo = ConvertTo-DateTime $Cert.valid_to
# For troubleshooting
#Write-Host $CertValidTo
$Certs += [PSCustomObject]@{Host=$Cert.hostname;Subject=$CertSubject;Status=$Cert.status;Expiredate=$CertValidTo;IssuerCA=$CertIssuer}
}
Im restlichen Skript wurden die einzelnen Daten mit einem vorgegebenen Wert gegen geprüft und die entsprechenden PRTG Ausgaben definiert.
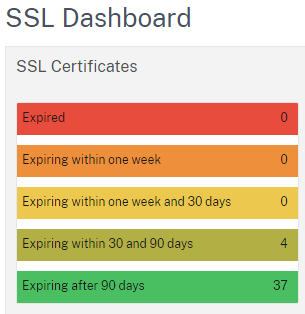
Das Script muss nun in den Custom Sensors Ordner von PRTG gelegt werden und der Sensor kann entsprechend eingerichtet werden:
Parameter gem. Script-Beschreibung, Securitykontext vom GerätAls primären Channel die bald ablaufenden Zertifikate, Intervall 12h und sofortiger DOWN Status auswählen
PRTG – Citrix ADM für zentrale ADC Überwachung nutzen
Es ist schon ein paar Tage her, da habe ich über PRTG Custom Sensoren für ADC geschrieben. Diese haben bisher mehr oder weniger gut in unserer Umgebung funktioniert. Für mich zeigten sich dabei jedoch mit der Zeit folgende Nachteile:
Jeder ADC, jedes ADC HA Paar muss im PRTG konfiguriert werden
Ist ein LB/CS vServer im DOWN Status, bleibt der PRTG Sensor rot, bis der vServer entweder wieder UP oder manuell deaktiviert ist (reaktivieren nicht vergessen)
Die Sensoren lieferten teils falsche/unvollständige Daten
Da wir sowieso eine ADM Appliance im Einsatz haben, suchte ich nach Möglichkeiten diese als Datenquelle anzusteuern. Mein erster Ansatz mit SNMP Traps scheiterte an der Tatsache, das PRTG dies nur einmalig als Alarm anzeigt und im nächsten Intervall wieder auf Status grün wechselt, falls nicht ein weiterer Trap gesendet wurde. Diese Option war daher für uns unbrauchbar.
Nach ein paar Recherchen bin ich auf ein Powershell Modul von Kenny Baldwin gestossen, welches mittels Nitro REST eine ADM Appliance mit div. Befehlen ansteuern kann. Das Original kann man auf GitHub herunterladen.
Das Modul hat ursprünglich vorgesehen, dass bei Benutzung die Anmeldedaten manuell eingegeben werden sollen. Für die Nutzung mit PRTG habe ich daher diesen Teil ein wenig angepasst, so dass die Daten aus dem PRTG Sensor übernommen werden können:
Citrix ADC SSL Bewertung optimieren – Stand Februar 2020
Im ursprünglichen Artikel bin ich auf die Basis-Schritte eingegangen, wie man bei Qualys die SSL Bewertung auf einen guten Stand bringen kann.
Da die Test-Routinen jeweils an die neusten Erkenntnisse angepasst werden, waren meine Bewertungen auf ein B gesunken, was für mich nicht hinnehmbar war. Hier möchte ich euch die Schritte beschreiben, wie ich wieder auf eine A+ Bewertung gekommen bin.
Der erste Schritt ist relativ einfach. Durch die aktivierten TLS 1.0 und TLS 1.1 wurde die Bewertung automatisch auf ein B heruntergestuft. Dazu kann man diese im virtuellen Server einfach in den SSL Parametern deaktivieren. Im gleichen Atemzug habe ich auch bereits TLS 1.3 aktiviert.
set ssl vserver nsgw-vsrv-gateway.domain.pit -tls1 DISABLED -tls11 DISABLED -tls13 ENABLED
Der nächste Schritt beinhaltet die Anpassung der Cipher Suites. Bei Qualys findet man einen direkten Link mit der Auflistung passender Algorithmen. Nebst dem bestehenden TLS 1.2 habe ich auch gleich diese für TLS 1.3 hinzugefügt. Man kann einerseits die bestehende Gruppe anpassen oder wie ich eine neue Gruppe erstellen:
Vor knapp zwei Jahren erstellte ich hier einen Artikel, wie man grundsätzlich einen SMTP Relay mit NetScaler konfigurieren kann (hier). Im Rahmen einer Datacenter Migration kam das Thema ACL für diesen Relay auf. Im genannten Artikel wurde sauber beschrieben, wie man den Exchange auf den ADC als Quelle konfigurieren kann. Wie kann man nun aber die Quellen seitens Loadbalancer einschränken?
Wer schon mit dem ADC gearbeitet hat weiss, dass dieser Access Control List (ACL) als Funktion bietet, jedoch ist die Konfiguration dieser eher statisch als dynamisch. Ich arbeite jedoch in einem Umfeld, in welchem die zugelassenen Server immer wieder mal ändern können (bei über 1000 Servern kein Wunder). Daher habe ich ein wenig Recherchiert und bin auf einen Lösungsansatz mittels Responder Policies gestossen, welchen ich hier dokumentiere.
Als erstes muss das Loadbalancing für den SMTP Relay konfiguriert werden. Ich nehme dazu als Basis den letzten Artikel und schmücke diesen mit ein wenig mehr Backend-Servern aus:
Nun bauen wir unsere Responder Policy. Damit die Pflege der Quell IPs ein wenig einfacher ist, nutzen wir dazu die sogenannten Data Sets (ähnlich wie Pattern Sets, jedoch für Daten wie IP Adressen) und verweisen in unserer Policy darauf. Als Aktion nehmen wir die vordefinierten „RESET“ Aktion.
Schlussendlich müssen wir nur doch die neu erstellte Policy dem SMTP Relay Loadbalancer zuweisen und ab sofort nimmt dieser nur noch Anfragen von IPs an, welche im Data Set „DS_MailRelay“ definiert sind.
Bei meinem aktuellen Arbeitgeber steht die Migration in zwei neue Rechenzentren an. Eines der Ziele dieser Migration ist die Erhöhung der Ausfallsicherheit. Dies habe ich zum Anlass genommen mir den PRTG Failover Cluster mit einem vorgeschalteten Citrix ADC einmal anzuschauen.
Die Installation und Konfiguration ist eigentlich recht einfach und das Vorgehen möchte ich in diesem Artikel nochmals erläutern.
Wenn man sich an diese hält, läuft der Cluster in kürzester Zeit. Was gibt es zu beachten?
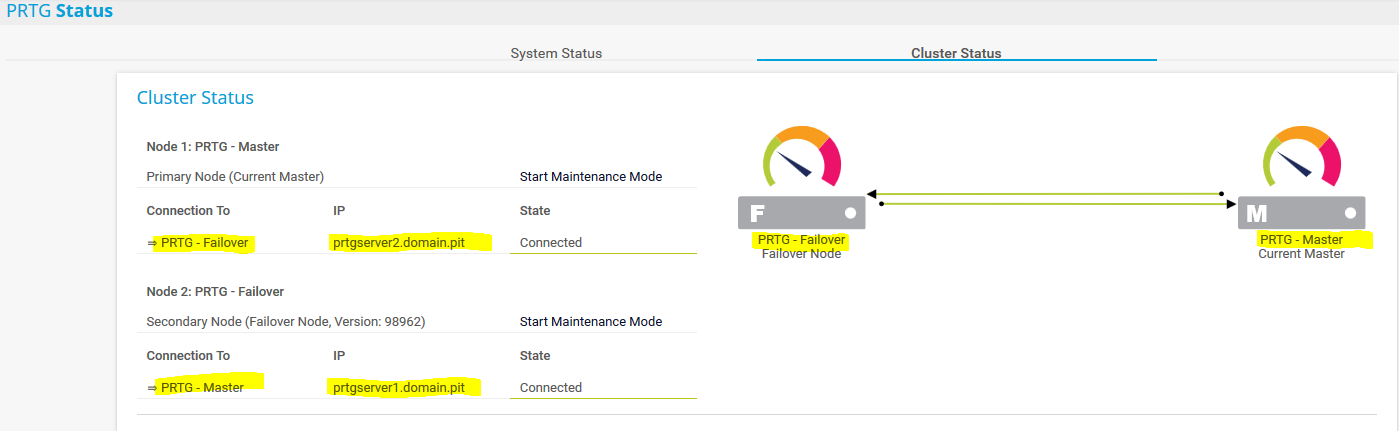
Der zweite Cluster-Node ist immer Read-Only, d.h. selbst bei einem Ausfall des Master-Servers kann auf dem Failover-Server nur überwacht, jedoch nicht konfiguriert werden.
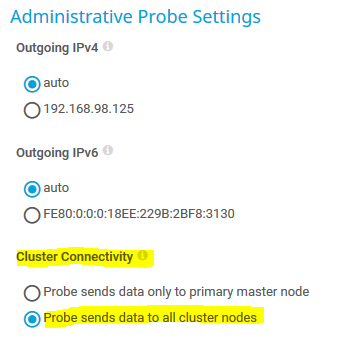
Remote Probes müssen so (um-)konfiguriert werden, dass sie ihre Daten an alle Cluster Nodes senden und nicht nur dem Master.
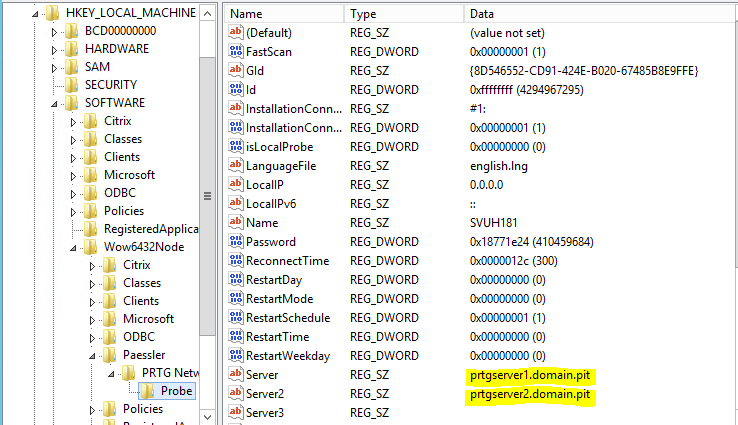
Die Remote Probes werden vom PRTG Cluster selbst konfiguriert. Eine allfällige Registry Anpassung (manuell oder via GPP) wird wieder überschrieben.
Remote Probes müssen jeden Cluster Node einzeln erreichen können. Bei einer NAT Konfiguration bedeutet dies ein eigener FQDN und NAT Zugang pro Core Server.
Der erste Administrator (prtgadmin) ist autonom pro Node. Um spätere Probleme zu vermeiden sollte das Passwort auf beiden Servern identisch gesetzt und mit der AD Authentifizierung gearbeitet werden.
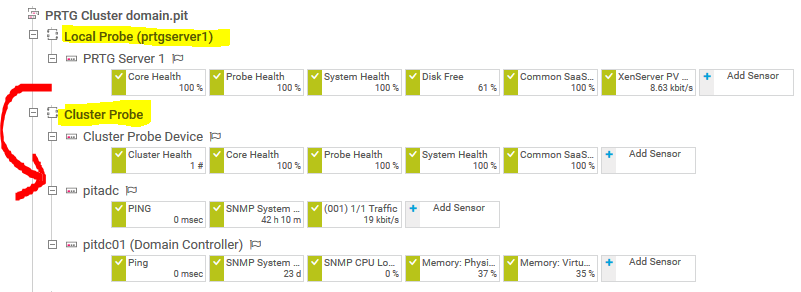
Nur der Master-Server sieht sich selbst noch als „Local Probe“. Auf den Failover-Servern ist nur der „Cluster Probe“ und alle anderen Remote Probe Server ersichtlich.
Die Probe Dienste der PRTG Core Server senden ihre Daten nur lokal (127.0.0.1).
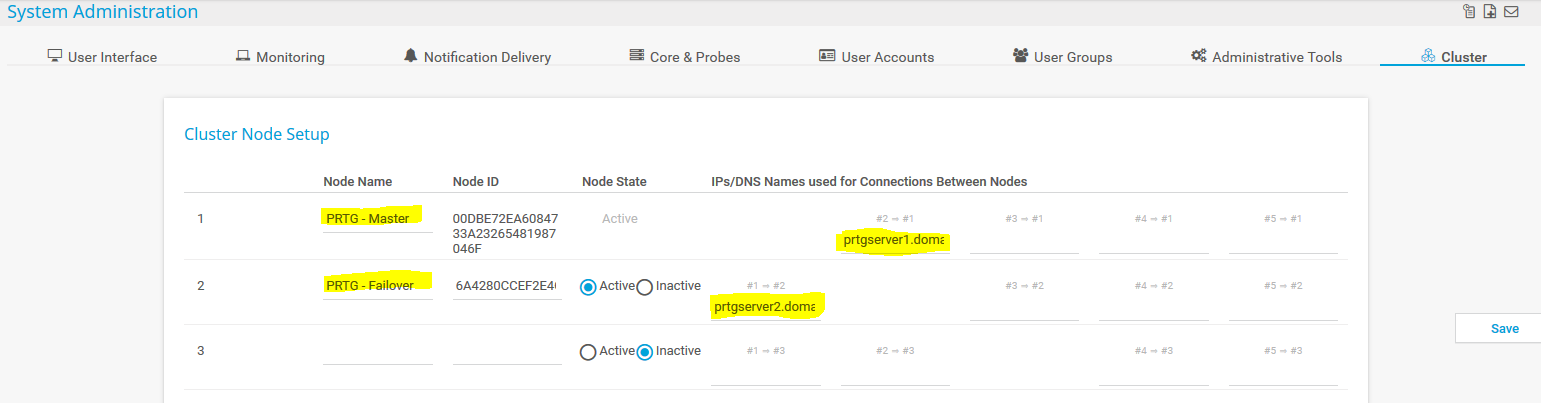
In den Cluster Einstellungen sollte man die „Node Namen“ passend setzen und die IP Adressen durch FQDN ersetzen. Dies macht es einerseits übersichtlicher für alle PRTG Benutzer und andererseits ist man unabhängiger bei einer allfälligen Änderung der IP Adressierung.
Kontrolle in der Registry auf einem Remote Probe Server
Kontrolle im Cluster Status
Cluster-Konfiguration der Remote Probes
Hinweise: – Man kann zwar im GUI dem Master Server einen DNS Alias setzen, die Remote Probes erhalten jedoch immer den originalen Hostname übermittelt. – Die Änderung wird sofort an die Remote Probes übermittelt.
Bei einer frischen Installation kann nun die Konfiguration direkt in der Cluster Probe gestartet werden. Wurde ein Solo PRTG Core Server in einen Cluster umgewandelt, so müssen die konfigurierten Gruppen, Geräte und Sensoren vomr „Local Probe“ in den „Cluster Probe“ verschoben werden:
Konfiguration Citrix ADC
Nachdem nun der PRTG Failover Cluster soweit konfiguriert ist, bauen wir nun den Zugriff auf diesen. Ohne ADC würde man nun entweder mittels DNS Round-Robin einen FQDN konfigurieren, wobei man hier nicht steuern kann auf welchem Node man landet, oder man arbeitet mit zwei verschiedenen FQDN, was wiederum nicht Anwenderfreundlich ist.
In diesem Abschnitt wird die Konfiguration eines LB vServer mit Failover Funktion erläutert.
Hierzu werden alle (normalerweise zwei) Cluster Nodes im ADC erfasst:
add server prtgserver1 prtgserver1.domain.pit add server prtgserver2 prtgserver2.domain.pit
Für jeden Server erstellen wir einen Service. Nach best practice sind die PRTG Server SSL verschlüsselt, somit bauen wir passende Services dazu:
add service svc-https-prtgserver1 prtgserver1 SSL 443 add service svc-https-prtgserver2 prtgserver2 SSL 443
Im Gegensatz zu einem normalen Loadbalancing wird im Failover nicht ein einzelner sondern zwei vServer benötigt, um den zweiten als Backup zu konfigurieren. Dem vServer mit einer IP wird der Service des PRTG Master Servers angefügt. Der zweite vServer (ohne Adressierung) steuert den PRTG Failover Server an. Beide LB vServer benötigen auch das dazu passende SSL Zertifikat:
set lb vserver lb-vsrv-prtg.domain.pit -backupVServer lb-vsrv-prtg-backup.domain.pit
Dem Service Monitoring habe ich am meisten Zeit gewidmet. Die PRTG Server bieten eine Status-Seite (/api/public/testlogin.htm), welche jedoch bereits bei einem Problem mit dem Mailserver ein „NOTOK“ zurück meldet. Nur diese Status-Seite alleine konnte ich also nicht nutzen. Daher baute ich ein Monitoring basierend auf dieser plus zusätzlichen zwei Standard-Monitoren (TCP und HTTP). Da sich der TCP-Default Monitor nicht anfügen lässt wenn bereits ein anderer Monitor in Benutzung ist, habe ich einen eigenen erstellt. Wegen der Benutzung von HTTPS muss dem HTTP Monitor der Response Code 302 hinzugefügt werden.
Das Monitoring der Status-Seite bat mir ein erstes Mal die Nutzung des „Reverse“ Monitorings. Würde man nämlich nur die Antwort „OK“ prüfen, so wäre der Monitor auch bei einem „NOTOK“ zufrieden, da „OK“ ein Bestandteil der Antwort ist. Daher prüfen wir auf ein „NOTOK“ und geben mit dem Monitor grünes Licht, falls diese Antwort nicht vorhanden ist – Reverse eben. ;-)
Zu guter Letzt müssen die neu gebauten Monitore in den Services konfiguriert werden. Dazu fügen wir pro Service die drei hinzu und definieren den Monitoring Schwellwert 2. So bleibt der Service verfügbar, solange zwei Monitore grünes Licht geben:
bind service svc-https-prtgserver1 -monitorName mon-prtg-http bind service svc-https-prtgserver1 -monitorName mon-prtg-TCP bind service svc-https-prtgserver1 -monitorName mon-prtg-Core-Status bind service svc-https-prtgserver2 -monitorName mon-prtg-http bind service svc-https-prtgserver2 -monitorName mon-prtg-TCP bind service svc-https-prtgserver2 -monitorName mon-prtg-Core-Status
set service svc-https-prtgserver1 -monThreshold 2 set service svc-https-prtgserver2 -monThreshold 2
Mit dieser Konfiguration kann nun ein Benutzer über eine FQDN (z.B. prtgcluster.domain.pit) auf die PRTG Oberfläche zugreifen. Der LB vServer vom ADC schaltet erst auf den Failover Server um, sobald der Master Server nicht mehr verfügbar ist (z.B. Neustart). Ist der Master Server wieder online, schaltet der ADC wieder auf diesen zurück.